


企业每投资1亿美元,即可获得50亿美元的token收益。
作者 | ZeR0
编辑 | 漠影
芯东西9月10日报道,昨晚,英伟达又放AI计算大招,推出专为长上下文推理和视频生成应用设计的新型专用GPU——NVIDIA Rubin CPX。
英伟达创始人兼CEO黄仁勋说:“正如RTX彻底改变了图形和物理AI一样,Rubin CPX是首款专为海量上下文AI打造的CUDA GPU,这种AI模型可以同时处理数百万个知识token的推理。”

Rubin CPX配备128GB GDDR7内存,NVFP4精度下AI算力可达30PFLOPS,非常适合运行长上下文处理(超过100万个token)和视频生成任务。
Vera Rubin NVL144 CPX平台可在单机架集成144张Rubin CPX GPU、144张Rubin GPU、36张Vera CPU,提供8EFLOPS的AI性能(NVFP4精度)和100TB的快速内存,内存带宽达到1.7PB/s。
其AI性能是英伟达Vera Rubin NVL144平台的2倍多,是基于Blackwell Ultra的GB300 NVL72系统的7.5倍,相比GB300 NVL72系统还能提供3倍更快的注意力机制。
Rubin CPX GPU预计将于2026年底上市。
9月17日,智猩猩发起主办的2025全球AI芯片峰会将在上海举办。大会设有主论坛,大模型AI芯片、AI芯片架构两大专题论坛,以及存算一体、超节点与智算集群两大技术研讨会,近40位嘉宾将分享和讨论。IEEE Fellow王中风教授将开场,华为昇腾等国产AI芯片力量集结,华为云、阿里云领衔超节点与智算集群势力。扫码报名~
01.
全新专用GPU:
128GB内存,30PFLOPS算力
Rubin CPX基于NVIDIA Rubin架构构建,采用经济高效的单芯片设计,配备128GB GDDR7内存,采用NVFP4精度,并经过优化,算力可达30PFLOPS,能够为AI推理任务,尤其是长上下文处理(超过100万个token)和视频生成,提供了远超现有系统的性能和token收益。
与英伟达GB300 NVL72系统相比,这款专用GPU还提供了3倍更快的注意力机制,从而提升了AI模型处理更长上下文序列的能力,而且速度不会降低。
相比之下,今年3月发布的Rubin GPU,在FP4精度下峰值推理能力为50PFLOPS。而英伟达在今年6月才公布创新型4位浮点格式NVFP4,这种格式的目标是在超低精度下力求保持模型性能。
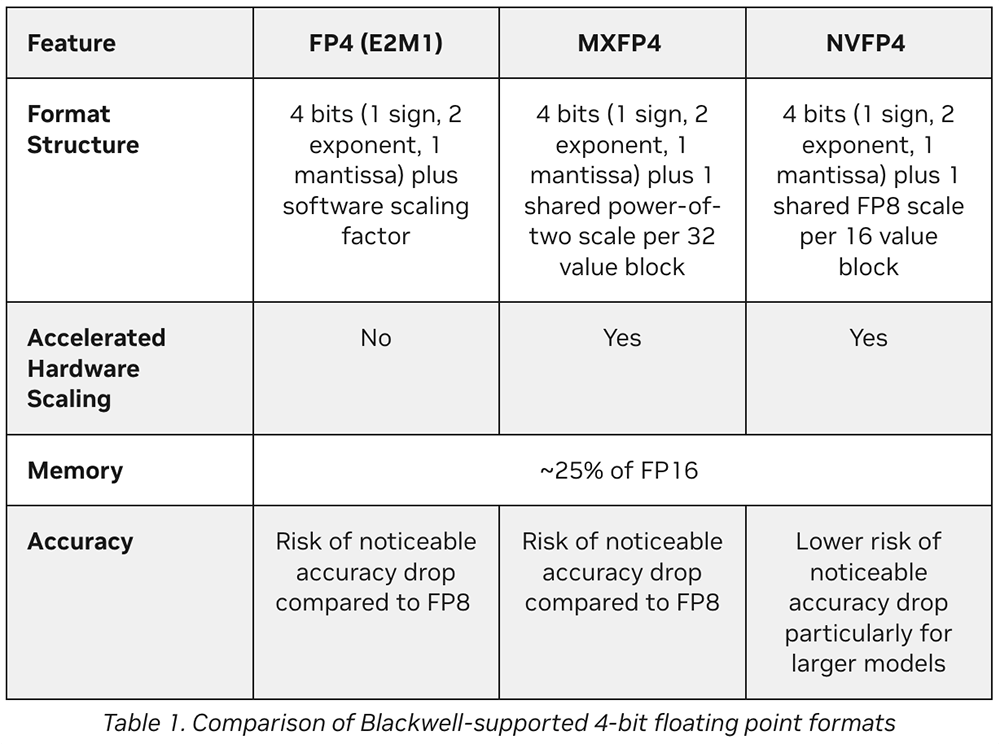
其分析表明,当使用训练后量化(PTQ)将DeepSeek-R1-0528从原始FP8格式量化为NVFP4格式时,其在关键语言建模任务上的准确率下降幅度不超过1%。在AIME 2024中,NVFP4的准确率甚至提高了2%。
Rubin CPX采用的GDDR7,价格比Rubin GPU配备的288GB HBM4高带宽内存更便宜。
02.
单机架AI性能达8EFLOPS,
提供100TB快速内存、1.7PB/s内存带宽
Rubin CPX与全新NVIDIA Vera Rubin NVL144 CPX平台中的英伟达Vera CPU和Rubin GPU协同工作,进行生成阶段处理,形成一个完整的高性能分解式服务解决方案。

Vera Rubin NVL144 CPX平台可在单机架集成144张Rubin CPX GPU、144张Rubin GPU、36张Vera CPU,提供8EFLOPS的AI性能(NVFP4精度)和100TB的快速内存,内存带宽达到1.7PB/s。
其AI性能是英伟达Vera Rubin NVL144平台的2倍多,是基于Blackwell Ultra的GB300 NVL72机架式系统的7.5倍。
英伟达还在周二分享了GB300 NVL72系统的基准测试结果,其DeepSeek-R1推理性能提升到上一代的1.4倍。该系统还创下MLPerf Inference v5.1套件中添加的所有新数据中心基准测试的记录,包括Llama 3.1 405B Interactive、Llama 3.1 8B、Whisper的记录。
英伟达计划为希望重复使用现有Vera Rubin 144系统的客户配备专用的Rubin CPX计算托盘(tray)。
Rubin CPX提供多种配置,包括Vera Rubin NVL144 CPX,可与NVIDIA Quantum‑X800 InfiniBand横向扩展计算架构或搭载英伟达Spectrum-XGS以太网技术和ConnectX-9 SuperNIC的Spectrum-X以太网网络平台结合使用。
英伟达预计将推出一款双机架产品,将Vera Rubin NVL144和Vera Rubin NVL144机架结合在一起,将快速内存容量提升至150TB。
03.
为分解式推理优化而生,
与英伟达旗舰GPU搭配用
这款全新的专用GPU,跟英伟达之前发布的旗舰GPU有什么区别?
据英伟达数据中心产品总监Shar Narasimhan分享,Rubin CPX将作为英伟达的专用GPU,用于上下文和预填充计算,从而显著提升海量上下文AI应用的性能。原版Rubin GPU则负责生成和解码计算。
推理由两个阶段组成:上下文阶段和生成阶段。这两个阶段对基础设施的要求截然不同。
上下文阶段受计算能力限制,需要高吞吐量处理来提取和分析大量输入数据,最终生成第一个token输出结果。
生成阶段受内存带宽限制,依赖于快速内存传输和高速互连(如NVLink)来维持逐token输出性能。
分解式推理使这些阶段能够独立处理,从而实现对计算和内存资源的有针对性的优化。这种架构转变可提高吞吐量,降低延迟,并提升整体资源利用率。
但分解会带来新的复杂性,需要在低延迟键值缓存传输、大语言模型感知路由和高效内存管理之间进行精确协调。
英伟达打造Rubin CPX GPU,就是为了在计算密集型长上下文阶段实现专业的加速,并将该专用GPU无缝集成到分解式基础架构中。
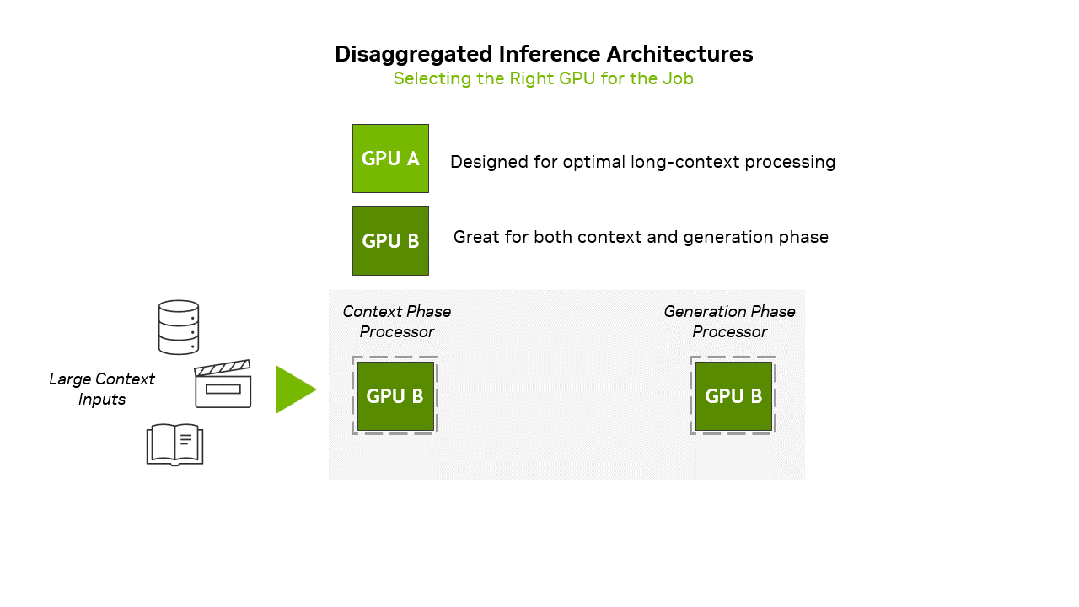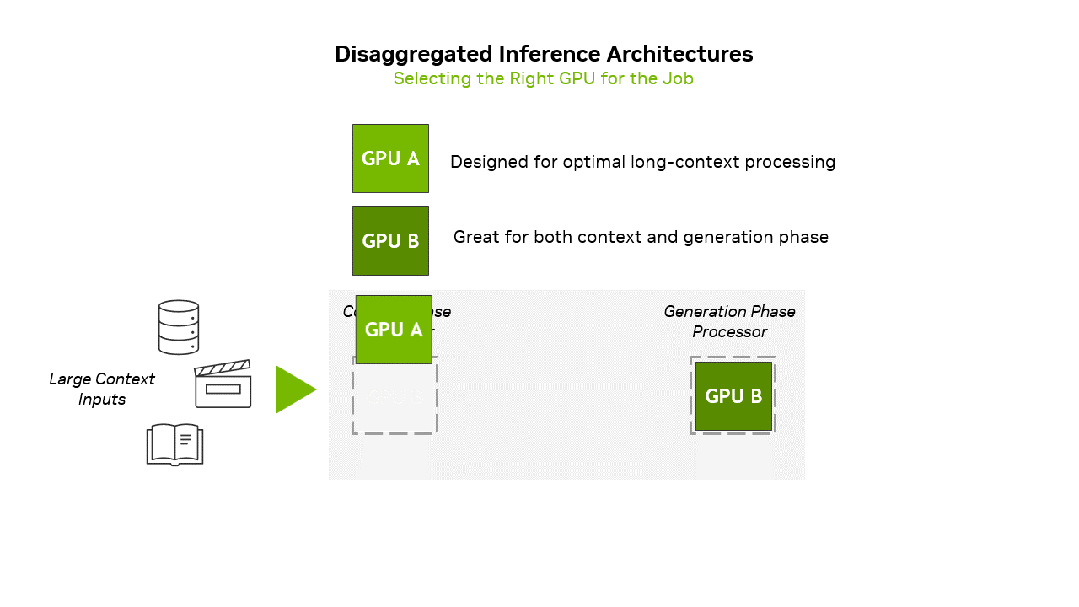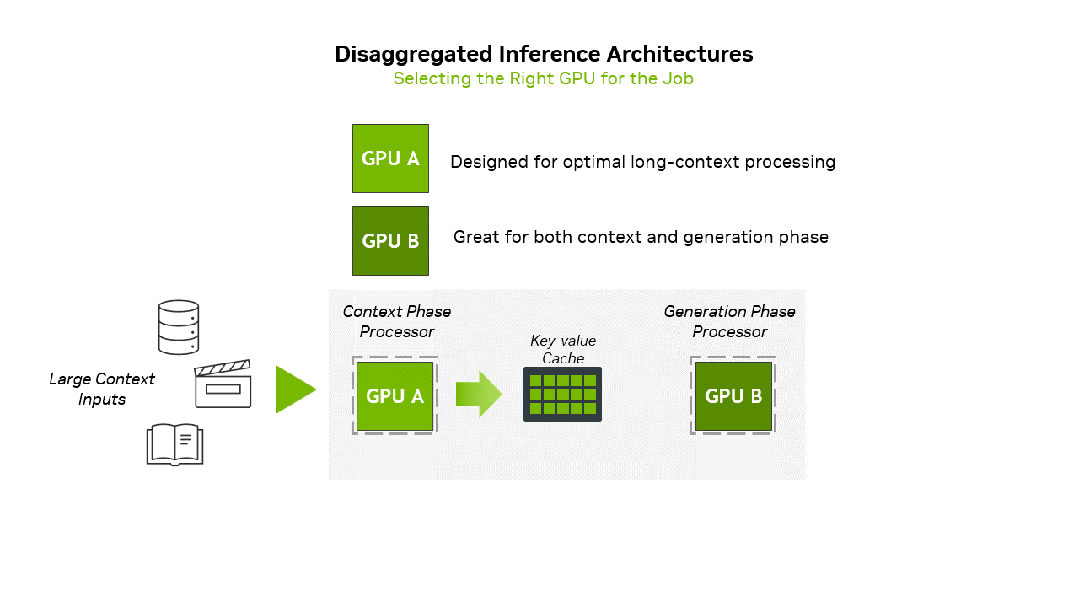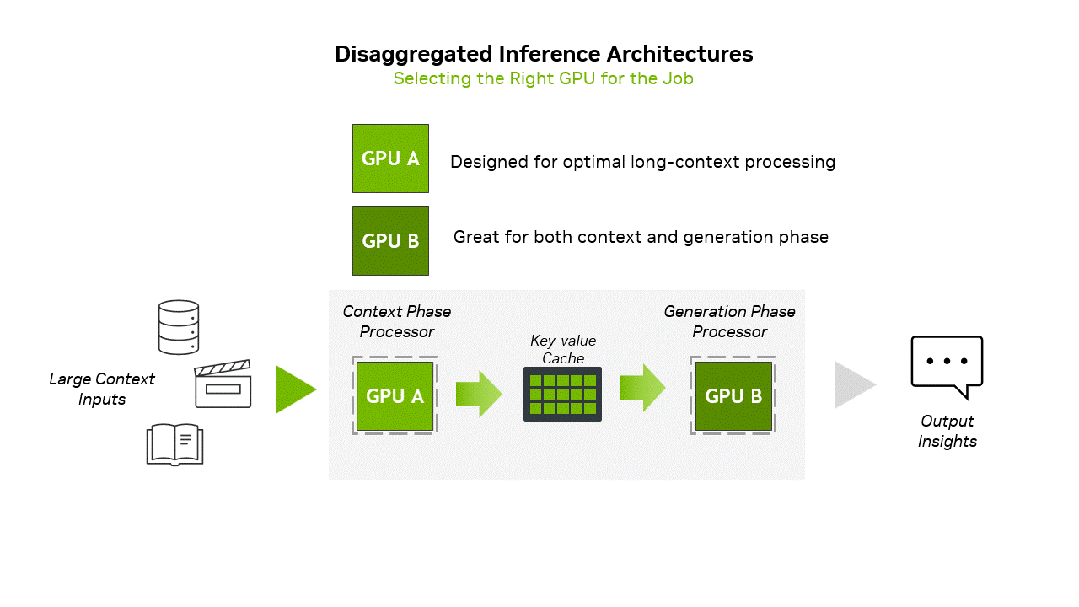
英伟达通过将GPU功能与上下文和生成工作负载相结合来优化推理。
Rubin CPX GPU专为高效处理长序列而优化,旨在增强长上下文性能,补充现有基础架构,提升吞吐量和响应速度,同时提供可扩展的效率,并最大化大规模生成式AI工作负载的投资回报率(ROI)。
为了处理视频,AI模型可能需要处理1小时内容中多达100万个token,这挑战了传统GPU计算的极限。Rubin CPX将视频解码器和编码器以及长上下文推理处理集成在单芯片中,为视频搜索和高质量生成视频等应用提供了前所未有的功能。
Rubin CPX将能够运行NVIDIA Nemotron系列最新的多模态模型,为企业级AI agent提供最先进的推理能力。对于生产级AI,Nemotron模型可以通过NVIDIA AI Enterprise软件平台交付。
04.
结语:30~50倍投资回报率,
每投资1亿美元可带来50亿美元收益
Vera Rubin NVL144 CPX采用英伟达Quantum-X800 InfiniBand或Spectrum-X以太网,搭配ConnectX-9 SuperNIC并由Dynamo平台协调,旨在为下一波百万token上下文AI推理工作负载提供支持,降低推理成本。
在规模化运营下,该平台可实现30~50倍的投资回报率,相当于每1亿美元的资本支出即可带来高达50亿美元的token收益。英伟达称这“为推理经济学树立了新的标杆”。
Rubin CPX将使AI编程助手从简单的代码生成工具转变为能够理解和优化大型软件项目的复杂系统。
知名的美国AI编程平台Cursor、AI视频生成创企Runway、AI编程创企Magic等正在探索用Rubin CPX GPU加速他们的代码生成、复杂视频生成等应用。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






